Adam Hájek
Affiliate Manager
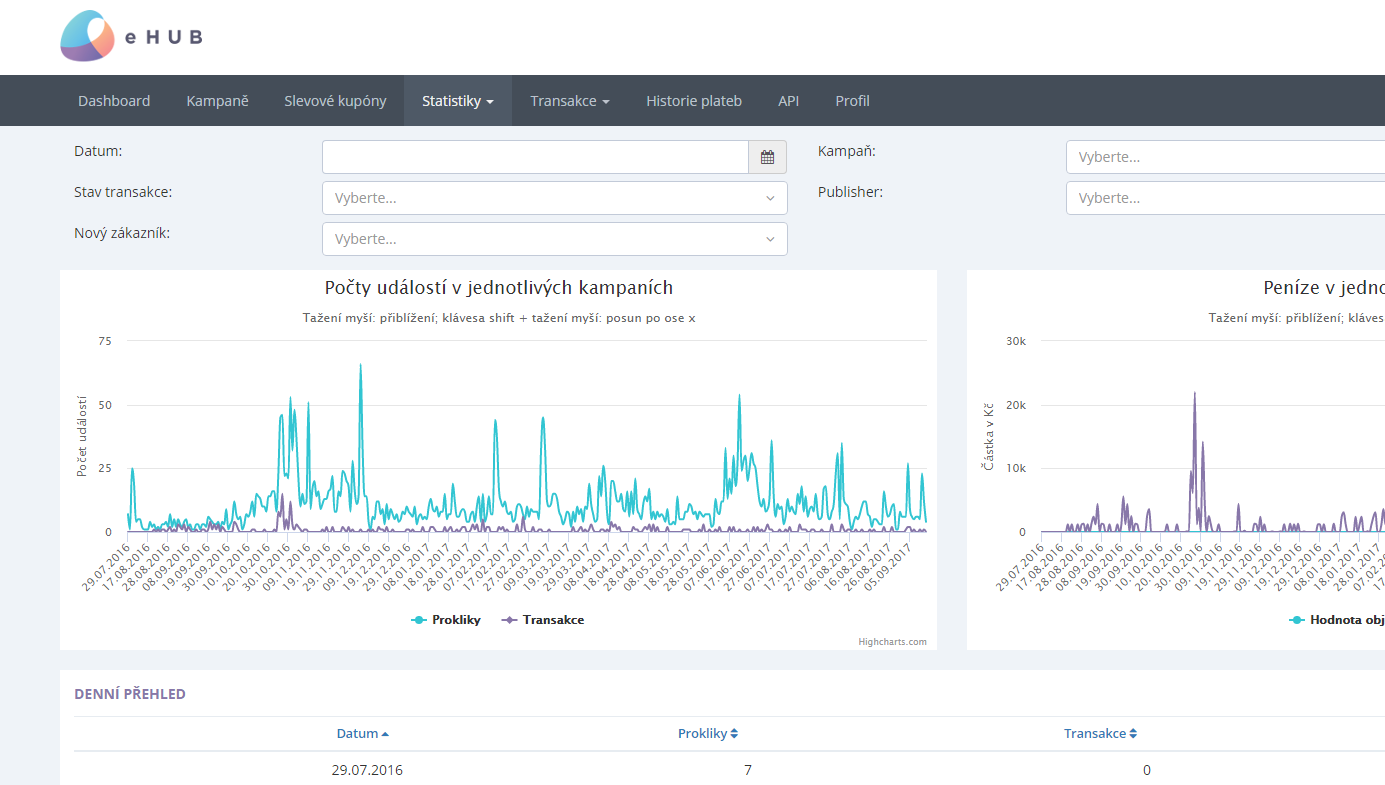
Generování podrobných statistik kampaní tak, aby je bylo možné jednoduše a rychle filtrovat dle požadavků uživatele, nebylo ani pro náš systém vždy snadné. V dnešním příspěvku vás necháme nahlédnout pod pokličku technického řešení, jak jsme si s tímto problémem poradili my.
Znáte to především z globálních sítí – málokdo má real time statistiky pohromadě s ostatními. Na dnešní detailní výsledky se tak musíte podívat jinam než na zbytek. Po technické stránce je to s velkým objemem dat totiž celkem oříšek! V dnešním příspěvku vás necháme nahlédnout pod pokličku technického řešení, jak jsme si s tímto problémem poradili my.

Generování podrobných statistik kampaní tak, aby je bylo možné jednoduše a rychle filtrovat dle požadavků uživatele, nebylo ani pro náš systém vždy snadné. Jak bývá pro tento úkol zvykem, používali jsme skript spouštěný tzv. „cronem“. Čím více jsme však měli dat, tím více náročné na strojový výkon generování bylo. Naše stroje dostávaly dost zabrat a museli jsme najít jinou cestu.
Největší nevýhodou generování statistik cronem bylo, že jsme nemohli nabídnout aktuální čísla v reálném čase. Skript se spouštěl každých 5 minut, aby aktualizoval dnešní statistiky. Opravy statistik za předchozí dny probíhaly jen jednou denně během noci. Dat bylo tolik, že generování nešlo spustit přes den při normální zátěži.
1. Co nejvíce snížit zátěž na naše stroje
2. Zákazníkům nabídnout statistiky v reálném čase
Přemýšleli jsme o různých nových technologiích, ale nakonec jsme finální řešení postavili na technologiích, které už máme a známe.
Většinu dat máme uloženou v databázi MySQL. Již před časem jsme byli kvůli rychlosti nuceni přidat databázi druhou, tzv. „slave“. Mezi hlavní databází a slave databází pak probíhá tzv. „replikace“ dat. Hlavní databáze data ukládá ve speciálním binárním formátu a slave databáze si je v reálném čase stahuje, aby měla stejná data jako hlavní databáze.
Jak tento již zavedený proces využít? Vytvořili jsme prototyp aplikace pomocí knihovny python-mysql-replication, která se umí stejně jako slave databáze připojit na hlavní databázi a v reálném čase tak přijímat veškeré změny, které v databázi proběhnou. Ty pak propisuje již agregované do speciální tabulky v hlavní databázi, která je určena pro zobrazení statistik v systému.
Po prvních lapsech, kdy nám čísla v některých případech neseděla, a důkladném testování nyní pomocí tohoto „agregátoru“ generujeme veškeré statistiky. Agregátor reaguje na aktuální změny v databázi, zátěž oproti dávkovému zpracování je jen mírná a jsme schopni vám poskytnout statistiky v reálném čase.
Agregátor nyní zvládne propagovat do tabulky statistik i tisíce změn za vteřinu bez významného vytížení našich serverů. Jsme tak perfektně připraveni na téměř jakoukoliv zátěž.



